번째 클러스터의 중심을 , 클러스터에 속하는 점의 집합을 라고 할 때, 전체 분산은 다음과 같이 계산된다.
이 값을 최소화하는 을 찾는 것이 알고리즘의 목표가 된다.
알고리즘은 우선 초기의 를 임의로 설정하는 것으로 시작한다. 그 다음에는 다음의 두 단계를 반복한다.
클러스터 설정: 각 점에 대해, 그 점에서 가장 가까운 클러스터를 찾아 배당한다.
클러스터 중심 재조정: 를 각 클러스터에 있는 점들의 평균값으로 재설정해준다.
만약 클러스터가 변하지 않는다면 반복을 중지한다.
맨 처음, 각 점들을 k개 집합으로 나눈다. 이때 임의로 나누거나, 어떤 휴리스틱 기법을 사용할 수도 있다. 그 다음 각 집합의 무게 중심을 구한다. 그 다음, 각각의 점들을 방금 구한 무게중심 가운데 제일 가까운 것에 연결지음으로써 새로이 집합을 나눌 수 있다. 이 작업을 반복하면 점들이 소속된 집합을 바꾸지 않거나, 무게중심이 변하지 않는 상태로 수렴될 수 있다.
이 알고리즘은 간단한 구조를 가지고 있고 많은 환경에서 빠르게 수렴하기 때문에(보통은 처음 주어진 데이터의 개수보다 훨씬 적은 반복만 필요하다) 널리 사용된다. 하지만 이 알고리즘이 다항을 넘는(superpolynomial) 시간()이 걸리는 경우도 존재한다. Smoothed analysis 경우의 복잡도는 다항 시간이다.
이 알고리즘은 전역 최적값을 보장해 주지 않는다. 맨 처음 나눈 방법에 상당히 의존한 결과가 나오므로 초기 클러스터 설정에 따라서는 실제 최적값보다 꽤 나쁜 값을 얻을 수도 있다. 이를 방지하기 위해서는, 서로 다른 초기값으로 여러 번 시도하여 가장 좋은 결과를 사용하는 기법 등을 사용할 수 있다.
또한, 이 알고리즘은 구하려는 클러스터의 갯수를 미리 정해 두어야 한다. 클러스터 갯수를 너무 많이 설정하면 큰 클러스터가 여러 개로 나뉘는 결과를 얻을 수도 있다.
public class KMeans { Dataset m_dataset; int m_clusterSize; int m_maxIteration; int m_recordCount; int m_fieldCount; int m_recordClusterIndex[]; // 각 레코드에 대하여 소속 군집번호 int m_clusterCount[]; // 각 클러스터별 소속 개수 Record m_cetroids[];
public KMeans(Dataset ds, int clusterSize, int maxIteration) { m_dataset = ds; this.m_clusterSize = clusterSize; this.m_maxIteration = maxIteration; this.m_recordCount = ds.getRecordCount(); this.m_fieldCount = ds.getAttrCount(); this.m_recordClusterIndex = new int[ ds.getRecordCount() ]; this.m_cetroids = new Record[ this.m_clusterSize ]; this.m_clusterCount = new int[ this.m_clusterSize ]; }
public void learn(){ // 초기 랜덤 시드 결정 int i=0; init_centroid(); this.print_centroid();
while(true){ //System.out.println( i + "번재 수행결과");
// 최대반복횟수에 의한 학습 종료 i++; if( i >= this.m_maxIteration){ System.out.println("최대반복횟수에 도달하여 종료합니다. 반복횟수 : " + i); break; }
// 중심점(Centroid)의 고정에 의한 학습 종료 // -- 새로운 중심점의 계산 // -- 이전 중심점과의 차이를 계산 // -- 만약 중심점의 변화가 없으면 끝
} System.out.println( i + "번재 수행결과"); System.out.println(); this.print_centroid(); this.print_state();
}
/** * 초기에 클러스터 개수만큼의 레코드를 선택하여 이들을 초기 군집 중심으로 합니다. * 이때 같은 레코드가 중복해서 다른 군집의 중심점이 되지 않도록 합니다. */ public void init_centroid(){ Random random = new Random(); for(int c=0; c<this.m_clusterSize; c++){ this.m_cetroids[c] = this.m_dataset.getRecord( random.nextInt(m_recordCount-1)).copy(); } }
/** * 군집의 중심을 새롭게 계산합니다. * 모든 레코드의 소속값을 고려하여 평균값을 정합니다. */ public void findNewCentroid_Step(){ // 초기화 for(int c=0; c<this.m_clusterSize; c++){ this.m_clusterCount[c] = 0; for(int f=0; f<this.m_fieldCount; f++){ this.m_cetroids[c].add(f, 0.0); } } int c_num; // 클러스터별 소속 레코드 개수를 계산합니다. for(int r=0; r<this.m_recordCount; r++){ c_num = this.m_recordClusterIndex[r]; this.m_clusterCount[c_num]++; } // 클러스터별 중심을 계산합니다. for(int r=0; r<this.m_recordCount; r++){ c_num = this.m_recordClusterIndex[r]; Record record = this.m_dataset.getRecord(r).copy(); for(int f=0; f<this.m_fieldCount; f++){ this.m_cetroids[c_num].addOnPrevValue(f, record.getValue(f)); } } for(int c=0; c<this.m_clusterSize; c++){ //System.out.println("군집 " + c + "의 개수 : " + this.m_clusterCount[c]); this.m_cetroids[c].multiply( 1.0/(double)this.m_clusterCount[c] ); } }
/** * 주어진 중심에 대하여 모든 레코드들을 지정(Assign)합니다. * 레코드와 각 군집중심과의 거리를 계산해보고 가장 거리가 가까운 군집에 지정합니다. */ public void reAssign_Step(){ int c_num; double min_dist = Double.POSITIVE_INFINITY; double distance; for(int r=0; r<this.m_recordCount; r++){ Record record = this.m_dataset.getRecord(r).copy(); c_num = 0; min_dist = 10000; //Double.POSITIVE_INFINITY; for(int c=0; c<this.m_clusterSize; c++){ distance = this.m_dataset.getDistanceOfUclideanP(record, this.m_cetroids[c]); // 해당 레코드와 군집중심과의 거리를 계산합니다. if(distance < min_dist){ // 최소 min_dist = distance; c_num = c; } } this.m_recordClusterIndex[r] = c_num; } }
/** * 현재 중심점(Centroid)의 값을 출력합니다. */ public void print_centroid() { for (int c = 0; c < this.m_clusterSize; c++) { System.out.println("군집[" + (c) + "]의 중심점 : " + this.m_cetroids[c].toString()); } }
비계층적 군집 방법(Non-Hierarchical Clustering Method)인 K-평균(K-means) 알고리즘은 각 개체를 가장 가까운 중심점에 할당하는 방법으로 다음 절차에 따라서 군집을 형성합니다.
<그림 8> K-평균 알고리즘 수행 절차
- K개의 초기 중심점을 선택한다.
- 각 개체를 가장 가까운 중심점을 갖는 군집으로 할당한 후 새로운 군집의 중심점을 계산한다.
- 각 개체의 할당에 변화가 없을 때까지 위의 단계를 반복하여 최종적으로 K 개의 군집을 형성한다.
K-평균 군집법은 거리 행렬을 필요로 하지 않으므로 규모가 큰 자료에 적용이 용이합니다. 또한 단계마다 어느 군집에 할당된 개체의 소속이 변하지 않는 계층적 군집법과는 달리 매 단계마다 개체가 할당되는 군집이 다를 수 있습니다.
예를 들어 데이터가 <표 8>과 같고 데이터 분포도가 <그림 9>와 같을 때 클러스터의 수 K=2를 발견하기 위해서 K-평균(K-means) 알고리즘을 적용해 봅시다. 먼저, 각 개체 사이의 거리는 <표 9>와 같으며 초기 중심점으로 ID 1과 ID 3을 선택하여 거리를 구하면 <표 10>과 같습니다. 선택된 중심점인 ID 1과 ID 3을 기준으로 가까운 개체를 할당하여 군집을 만들면 <그림 10>과 같이 (1, 2, 6)과 (3, 4, 5)이라는 첫 번째 군집이 만들어집니다. 이것은 아직 완전한 군집이라 할 수 없고 생성된 군집을 가지고 <표 11>과 같이 새로운 중심점을 구한 뒤 다시 이 중심점과 각 개체들의 거리를 계산하면 <표 12>와 같습니다. 이때 (1, 2, 6) 군집에 있던 ID 6은 두 번째 군집화 작업에서는 <그림 11>과 같이 (1, 2)와 (3, 4, 5, 6)으로 재배치되어 다른 군집으로 할당됐습니다. 새로운 군집의 중심값으로 더 이상 개체가 할당하지 않으면 군집 작업은 여기서 마무리합니다.
<표 8> 수입과 명품 선호도 데이터 <그림 9> 수입과 명품 선호도 데이터 분포도 <표 9> 각 개체 사이의 거리 <표 10> K개의 초기 중심점과 각 개체 사이의 거리 <그림 10> 첫 번째 군집 생성 <표 11> 첫 번째 생성된 군집의 중심값 <표 12> 생성된 군집의 중심점과 각 개체 사이의 거리 <그림 11> 두 번째 군집 생성


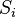



 KMeans군집소개_(050317)_090706.ppt
KMeans군집소개_(050317)_090706.ppt







