차근차근/OpenCV
std::vector<cv::String,std::allocator<cv::String>>ldata>
std::vector<cv::String,std::allocator<cv::String>>ldata>
http://www.hanbit.co.kr/network/view.html?bi_id=1606
4.1 vector의 자료구조
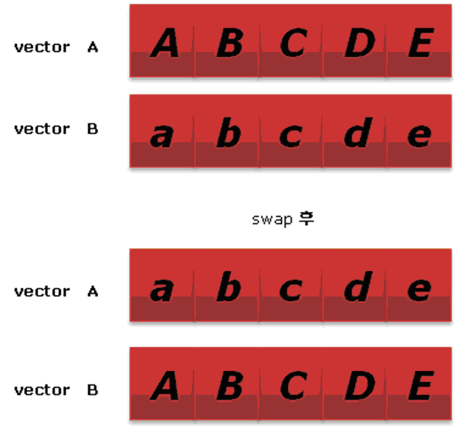
처음 말했듯이 vector의 자료구조는 배열과 비슷합니다. Wikipedia에서 배열은 “번호와 번호에 대응하는 데이터로 이루어진 자료구조를 나타냅니다. 일반적으로 배열에는 같은 종류의 데이터가 순차적으로 저장된다’고 설명합니다. 문자 A, B, C, D, E를 배열에 저장한다면 아래 그림과 같이 저장합니다.
[그림 1] A, B, C, D, E가 저장된 배열
배열의 크기는 고정이지만 vector는 동적으로 변하는 점이 vector와 배열 자료구조의 큰 차이점입니다.
4.2 배열의 특징
1. 배열의 크기는 고정이다.배열은 처음에 크기를 설정하면 이후에 크기를 변경하지 못합니다. 처음 설정한 크기를 넘어서 데이터를 저장할 수 없습니다. [그림 1]의 배열은 A, B, C, D, E만 저장할 수 있게 5개의 크기로 만들어져 있습니다. 배열은 크기가 고정이므로 더 이상 새로운 것을 넣을 수 없습니다.
2. 중간에 데이터 삽입, 삭제가 용이하지 않다.
배열은 데이터를 순차적으로 저장합니다. 중간에 데이터를 삽입하면 삽입한 위치 이후의 데이터는 모두 뒤로 하나씩 이동해야 합니다. 또 중간에 있는 데이터를 삭제하면 삭제한 위치 이후의 데이터는 모두 앞으로 하나씩 이동해야 합니다.
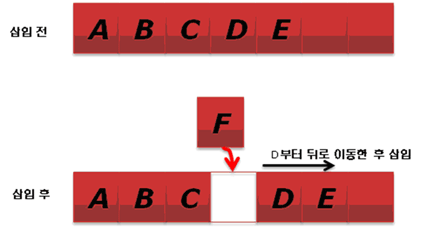
[ 그림 2] 중간에 삽입. F를 C와 D 사이에 삽입. D와 E를 뒤로 이동 시킨 후 빈 공간에 넣는다
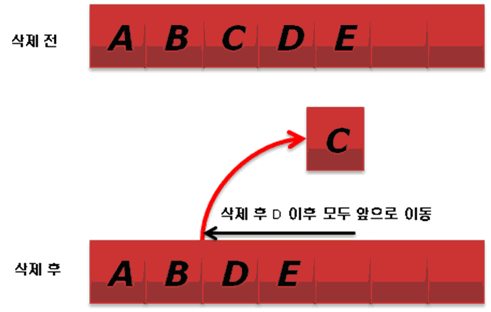
[그림 3] 중간에 삭제. C를 삭제. 삭제 후 D와 E가 앞으로 이동
3. 구현이 쉽다.
배열은 크기가 고정이며 중간 삭제 및 삽입에 대한 특별한 기능이 없는 아주 단순한 자료구조입니다. 제일 처음 프로그래밍을 배울 때 배우는 자료구조가 배열 일 정도로 구현이 쉽습니다.
4. 랜덤 접근이 가능하다.
배열은 데이터를 순차적으로 저장하므로 랜덤 접근이 가능합니다.
4.3 vector를 사용해야 하는 경우
1. 저장할 데이터 개수가 가변적이다.배열과 vector의 가장 큰 차이점은 ‘배열은 크기가 고정이고 vector는 크기가 동적으로 변한다’입니다. 저장할 데이터 개수를 미리 알 수 없다면 vector를 사용 하는 편이 좋습니다.
2. 중간에 데이터 삽입이나 삭제가 없다.
vector는 배열처럼 데이터를 순차적으로 저장합니다. 중간에 데이터 삭제 및 삽입을 하면 배열과 같은 문제가 발생합니다. vector는 가장 뒤에서부터 데이터를 삭제 하거나 삽입하는 경우에 적합합니다.
3. 저장할 데이터 개수가 적거나 많은 경우 빈번하게 검색하지 않는다.
데이터를 순차적으로 저장하므로 많은 데이터를 저장한다면 검색 속도가 빠르지 않습니다. 검색을 자주한다면 map이나 set, hash_map을 사용해야 합니다.
4. 데이터 접근을 랜덤하게 하고 싶다.
vector는 배열 같은 특성이 있어서 랜덤 접근이 가능합니다. 특정 데이터가 저장된 위치를 안다면 랜덤 접근을 사용하는 쪽이 성능이 좋고, 사용하기도 간편합 니다. 예를 들면 온라인 게임 제작 시 아이템 번호를 순차적으로 부여한다고 가정합니다. 아이템 데이터를 vector에 저장하면 아이템 개수가 늘어나더라도 코 드를 수정하지 않아도 되며, 아이템 코드 7번은 언제나 7번째 위치에 있으므로 랜덤 접근으로 빠르고 쉽게 접근할 수 있습니다. 위에 열거한 배열의 특징과 vector의 특징을 잘 숙지하여 기존에 배열을 사용한 부분에 vector를 사용하면 배열의 단점을 없앤 유지보수성이 좋은 코드를 만들게 됩니다.
4.4 vector vs. list
vector 사용법을 보면 list와 비슷한 부분도 있고 다른 부분도 있음을 알게 되리라 생각합니다. vector과 list의 차이점을 잘 이해한 후 올바르게 사용해야 됩니다 . vector와 list의 차이를 정리하면 아래 표와 같습니다.| vector | List | |
| 크기 변경 가능 | O | O |
| 중간 삽입, 삭제 용이 | X | O |
| 순차 접근 가능 | O | O |
| 랜덤 접근 가능 | O | X |
[표 1]을 보시면 아시겠지만 vector와 list의 차이점은 크게 2가지입니다.
- 중간 삽입, 삭제
- 랜덤 접근
[참고]
| 중간 삽입 삭제가 있다면 무조건 list를 사용해야 할까요? list와 vector의 차이점을 보면 중간 삽입, 삭제가 자주 일어나는 자료구조는 list 사용이 정답입니다. 그렇다고 list 사용이 항상 정답은 아닙니다. 만약 저장하는 데이터의 개수가 적고 랜덤 접근을 하고 싶은 경우에는 vector를 사용해도 좋습니다. 제가 하는 일을 예를 들면 대부분의 온라인 캐주얼 게임은 방을 만들어서 방에 들어온 유저끼리 게임을 합니다. 방은 유저가 들어 오기도 하고 나가기도 합니 다. 중간 삽입, 삭제가 자주 일어나지만 방의 유저 수는 대부분 적습니다. 이런 경우 중간 삽입, 삭제로 데이터를 이동해도 전체적인 성능 측면에서는 문제가 되지 않습니다. 방에 있는 유저를 저장한 위치를 알고 있다면 유저 데이터에 접근할 때 list는 반복문으로 해당 위치까지 순차적으로 접근해야 하지만 vector는 바로 랜덤 접근이 가능하고 성능면에서도 더 좋습니다. 또한, 방에 있는 모든 유저 데이터에 접근할 때 list는 반복자(Iterator)로 접근하지만, vector는 일반 배열 처럼 접근하므로 훨씬 간단하게 유저 데이터에 접근할 수 있습니다. 저장하는 데이터 개수가 적은 경우는 대부분 list 보다는 vector를 사용하는 편이 더 좋습니다. vector와 list의 차이점만으로 둘 중 어느 것을 사용할지 선택하기 보다는 전체적인 장, 단점을 파악하고나서 선택하는 것이 좋습니다. |
4.5 vector 사용 방법
vector를 사용하려면 vector 헤더 파일을 포함해야 합니다.#include <vector>vector 형식은 아래와 같습니다.
vector< 자료 type > 변수 이름vector를 int 형에 대해 선언했습니다.
vector< int > vector1;선언 후 vector를 사용합니다. vector도 list처럼 동적 할당이 가능합니다.
vector < 자료 type >* 변수 이름 = new vector< 자료 type >; vector< int >* vector1 = new vector< int>;
4.5.1 vector의 주요 멤버들
vector 멤버 중 일반적으로 자주 사용하는 멤버들은 아래와 같습니다.| 멤버 | 설명 |
|---|---|
| assign | 특정 원소로 채운다 |
| at | 특정 위치의 원소의 참조를 반환 |
| back | 마지막 원소의 참조를 반환 |
| begin | 첫 번째 원소의 랜던 접근 반복자를 반환 |
| clear | 모든 원소를 삭제 |
| empty | 아무것도 없으면 true 반환 |
| End | 마지막 원소 다음의(미 사용 영역) 반복자를 반환 |
| erase | 특정 위치의 원소나 지정 범위의 원소를 삭제 |
| front | 첫 번째 원소의 참조를 반환 |
| insert | 특정 위치에 원소 삽입 |
| pop_back | 마지막 원소를 삭제 |
| push_back | 마지막에 원소를 추가 |
| rbegin | 역방향으로 첫 번째 원소의 반복자를 반환 |
| rend | 역방향으로 마지막 원소 다음의 반복자를 반환 |
| reserve | 지정된 크기의 저장 공간을 확보 |
| size | 원소의 개소를 반환 |
| swap | 두 개의 vector의 원소를 서로 맞바꾼다 |
4.5.1.1 기본 사용 멤버
vector의 가장 기본적인(추가, 삭제, 접근 등) 사용법을 설명 하겠습니다. [표 3]과 [그림 4]를 참고 해주세요
| 멤버 | 원형 | 설명 |
|---|---|---|
| at | reference at( size_type _Pos ); const_reference at( size_type _Pos ) const; | 특정 위치의 원소의 참조를 반환 |
| back | reference back( ); const_reference back( ) const; | 마지막 원소의 참조를 반환 |
| begin | const_iterator begin() const; iterator begin(); | 첫 번째 원소의 랜덤 접근 반복자를 반환 |
| clear | void clear(); | 모든 원소를 삭제 |
| empty | bool empty() const; | 아무것도 없으면 true 반환 |
| end | iterator end( ); const_iterator end( ) const; | 마지막 원소 다음의(미 사용 영역) 반복자를 반환 |
| front | reference front( ); const_reference front( ) const; | 첫 번째 원소의 참조를 반환 |
| pop_back | void pop_back(); | 마지막 원소를 삭제 |
| push_back | void push_back( const Type& _Val ); | 마지막에 원소를 추가 |
| rbegin | reverse_iterator rbegin( ); const_reverse_iterator rbegin( ) const; | 역방향으로 첫 번째 원소의 반복자를 반환 |
| rend | const_reverse_iterator rend( ) const; reverse_iterator rend( ); | 역방향으로 마지막 원소 다음의 반복자를 반환 |
| size | size_type size() const; | 원소의 개수를 반환 |
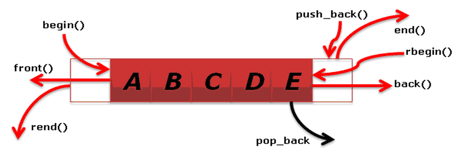
[그림 4] vector의 추가, 삭제, 접근 멤버를 나타내고 있다
추가
기본적으로 원소의 마지막 위치에 추가하며 push_back을 사용합니다. 처음이나 중간 위치에 추가할 때는 다음에 소개할 insert를 사용합니다.
vector< int > vector1; vector1.push_back( 1 );삭제
기본적으로 마지막 위치의 원소를 삭제하며 pop_back을 사용합니다. 처음이나 중간에 있는 원소를 삭제할 때는 다음에 소개할 erase를 사용합니다.
vector1.pop_back();접근
첫 번째 위치의 반복자를 반환할 때는 begin()을 사용합니다. 첫 번째 원소의 참조를 반환할 때는 front()를 사용합니다.
vector< int >::iterator IterBegin = vector1.begin(); cout << *IterBegin << endl; int& FirstValue = vector1.front(); const int& refFirstValue = vector1.front();마지막 다음의 영역(미 사용 영역)을 가리키는 반복자를 반환할 때는 end()를 사용합니다. 마지막 원소의 참조를 반환할 때는 back()을 사용합니다.
;
vector< int >::iterator IterEnd = vector1.end();
for(vector< int >::iterator IterPos = vector1.begin; IterPos != vector1.end();
++IterPos )
{
……..
}
int& LastValue = vector1.back();
const int& refLastValue = vector1.back();
rbegin()과 rend()는 방향이 역방향이라는 점만 다를 뿐, 나머지는 begin()과 end()와 같습니다. 특정 위치에 있는 원소를 접근할 때는 at()을 사용하면 됩니다.int& Value1 = vector1.at(0); // 첫 번째 위치 const int Value2 = vector1.at(1); // 두 번째 위치배열 식 접근도 가능합니다. vector를 사용할 때 보통 이 방식으로 자주 사용합니다.
int Value = vector1[0]; // 첫 번째 위치모두 삭제
저장한 모든 데이터를 삭제할 때는 clear()를 사용합니다.
vector1.clear();데이터 저장 여부
vector에 저장한 데이터가 있는지 없는지는 empty()로 조사합니다. empty()는 데이터가 있으면 false, 없다면 true를 반환합니다.
bool bEmpty = vector1.empty();vector에 저장된 원소 개수 알기
size()를 사용하여 vector에 저장 되어 있는 원소 개수를 조사합니다.
vector< int >::size_type Count = vector1.size();위에 설명한 멤버들을 사용하는 아래의 예제 코드를 보면서 vector의 기본 사용 방법을 정확하게 숙지해 주세요
[리스트 1] 온라인 게임의 게임 방의 유저 관리
#include <vector>
#include <iostream>
using namespace std;
// 방의 유저 정보
struct RoomUser
{
int CharCd; // 캐릭터 코드
int Level; // 레벨
};
void main()
{
// 유저1
RoomUser RoomUser1;
RoomUser1.CharCd = 1; RoomUser1.Level = 10;
// 유저2
RoomUser RoomUser2;
RoomUser2.CharCd = 2; RoomUser2.Level = 5;
// 유저3
RoomUser RoomUser3;
RoomUser3.CharCd = 3; RoomUser3.Level = 12;
// 방의 유저들을 저장할 vector
vector< RoomUser > RoomUsers;
// 추가
RoomUsers.push_back( RoomUser1 );
RoomUsers.push_back( RoomUser2 );
RoomUsers.push_back( RoomUser3 );
// 방에 있는 유저 수
int UserCount = RoomUsers.size();
// 방에 있는 유저 정보 출력
// 반복자로 접근 - 순방향
for( vector< RoomUser >::iterator IterPos = RoomUsers.begin();
IterPos != RoomUsers.end();
++IterPos )
{
cout << "유저코드 : " << IterPos->CharCd << endl;
cout << "유저레벨 : " << IterPos->Level << endl;
}
cout << endl;
// 반복자로 접근- 역방향
for( vector< RoomUser >::reverse_iterator IterPos = RoomUsers.rbegin();
IterPos != RoomUsers.rend();
++IterPos )
{
cout << "유저코드: " << IterPos->CharCd << endl;
cout << "유저레벨: " << IterPos->Level << endl;
}
cout << endl;
// 배열 방식으로 접근
for( int i = 0; i < UserCount; ++i )
{
cout << "유저 코드 : " << RoomUsers[i].CharCd << endl;
cout << "유저 레벨 : " << RoomUsers[i].Level << endl;
}
cout << endl;
// 첫 번째 유저 데이터 접근
RoomUser& FirstRoomUser = RoomUsers.front();
cout << "첫 번째 유저의 레벨 : " << FirstRoomUser.Level << endl << endl;
RoomUser& LastRoomUser = RoomUsers.back();
cout << "마지막 번째 유저의 레벨: " << LastRoomUser.Level << endl << endl;
// at을 사용하여 두 번째 유저의 레벨을 출력
RoomUser& RoomUserAt = RoomUsers.at(1);
cout << "두 번째 유저의 레벨: " << RoomUserAt.Level << endl << endl;
// 삭제
RoomUsers.pop_back();
UserCount = RoomUsers.size();
cout << "현재 방에 있는 유저 수: " << UserCount << endl << endl;
// 아직 방에 유저가 있다면 모두 삭제한다.
if( false == RoomUsers.empty() )
{
RoomUsers.clear();
}
UserCount = RoomUsers.size();
cout << "현재 방에 있는 유저 수: " << UserCount << endl;
}
결과 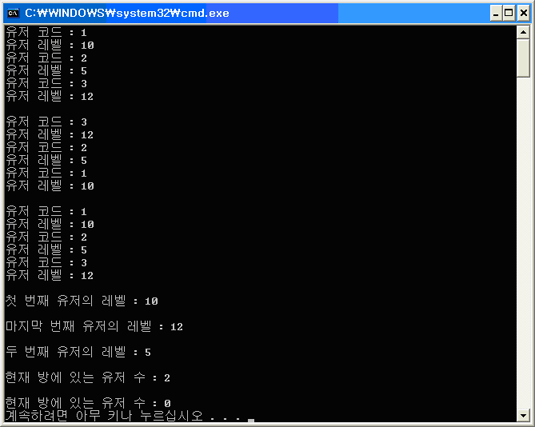
혹시 랜덤 접근이 무엇인지 잘 이해하지 못한 분은 [리스트 1]의 예제 코드에서 배열 방식으로 접근하는 부분을 잘 보세요. 배열처럼 접근 하는 것을 랜덤 접근 이 가능하다고 말합니다. 랜덤 접근이 안 되는 list에서는 오직 반복자로 순차 접근만 가능합니다.
4.5.1.2 insert
insert는 지정된 위치에 삽입하며, 세 가지 방식이 있습니다. list의 insert와 사용 방법이 같습니다. 세 가지 원형은 각각 지정한 위치에 삽입, 지정한 위치에 지 정한 개수만큼 삽입, 지정한 위치에 지정 범위에 있는 것을 삽입합니다. vector의 insert를 사용할 때에는 삽입한 위치 이후의 원소들이 모두 뒤로 이동함을 꼭 숙지하셔야 됩니다.
원형 : iterator insert( iterator _Where, const Type& _Val );
void insert( iterator _Where, size_type _Count, const Type& _Val );
template<class InputIterator> void insert( iterator _Where, InputIterator _First,
InputIterator _Last );

[그림 5] vector의 insert
첫 번째 insert는 지정한 위치에 데이터를 삽입합니다.
vector< int >::iterator iterInsertPos = vector1.begin(); vector1.insert( iterInsertPos, 100 );이 코드는 100을 첫 번째 위치에 삽입합니다. 두 번째 insert는 지정한 위치에 데이터를 횟수만큼 삽입합니다.
iterInsertPos = vector1.begin(); ++iterInsertPos; vector1.insert( iterInsertPos, 2, 200 );두 번째 위치에 200을 두 번 추가합니다. 세 번째 insert는 지정한 위치에 복사 할 vector의 (복사하기를 원하는 영역의)시작과 끝 반복자가 가리키는 영역의 모 든 요소를 삽입합니다.
vector< int > vector2; list2.push_back( 500 ); list2.push_back( 600 ); list2.push_back( 700 ); iterInsertPos = vector1.begin(); vector1.insert( ++iterInsertPos, vector2.begin(), vector2.end() );vector1의 두 번째 위치에 vector2의 모든 요소를 삽입합니다. 위에서 설명한 insert의 세 가지 방법을 사용한 전체 코드입니다. 참고로 이 예제는 이전 회의 list 의 insert에서 소개했던 코드와 같습니다. 오직 list 대신 vector를 사용했다는 것만 다릅니다.
[리스트 2] insert 사용
void main()
{
vector< int > vector1;
vector1.push_back(20);
vector1.push_back(30);
cout << "삽입 테스트 1" << endl;
// 첫 번째 위치에 삽입한다.
vector< int >::iterator iterInsertPos = vector1.begin();
vector1.insert( iterInsertPos, 100 );
// 100, 20, 30 순으로 출력한다.
vector< int >::iterator iterEnd = vector1.end();
for(vector< int >::iterator iterPos = vector1.begin();
iterPos != iterEnd;
++iterPos )
{
cout << "vector1 : " << *iterPos << endl;
}
cout << endl << "삽입 테스트 2" << endl;
// 두 번째 위치에 200을 2개 삽입한다.
iterInsertPos = vector1.begin();
++iterInsertPos;
vector1.insert( iterInsertPos, 2, 200 );
// 100, 200, 200, 20, 30 순으로 출력한다.
iterEnd = vector1.end();
for(vector< int >::iterator iterPos = vector1.begin();
iterPos != iterEnd;
++iterPos )
{
cout << "vector1 : " << *iterPos << endl;
}
cout << endl << "삽입 테스트 3" << endl;
vector< int > vector2;
vector2.push_back( 1000 );
vector2.push_back( 2000 );
vector2.push_back( 3000 );
// 두 번째 위치에 vecter2의 모든 데이터를 삽입한다.
iterInsertPos = vector1.begin();
vector1.insert( ++iterInsertPos, vector2.begin(), vector2.end() );
// 100, 1000, 2000, 3000, 200, 200, 20, 30 순으로 출력한다.
iterEnd = vector1.end();
for(vector< int >::iterator iterPos = vector1.begin();
iterPos != iterEnd;
++iterPos )
{
cout << "vector1 : " << *iterPos << endl;
}
}
결과 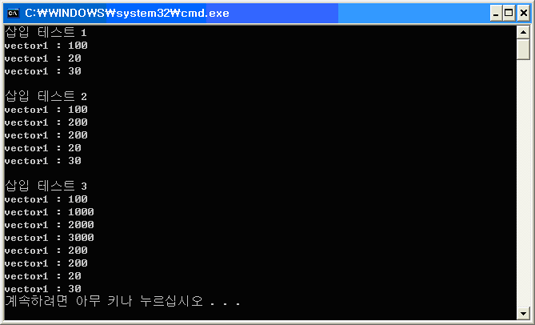
4.5.1.3 erase
반복자로 특정 위치의 요소를 삭제할 때는 erase를 사용합니다. 사용 방식은 두 가지가 있습니다. 하나는 지정한 위치의 요소를 삭제하고, 다른 하나는 지정한 범위의 요소를 삭제합니다. 마지막 위치 이외의 곳에서 erase를 할 때는 삭제한 위치 이후의 모든 원소들이 앞으로 이동한다는 것을 꼭 숙지하셔야 됩니다.
원형 : iterator erase( iterator _Where );
iterator erase( iterator _First, iterator _Last );
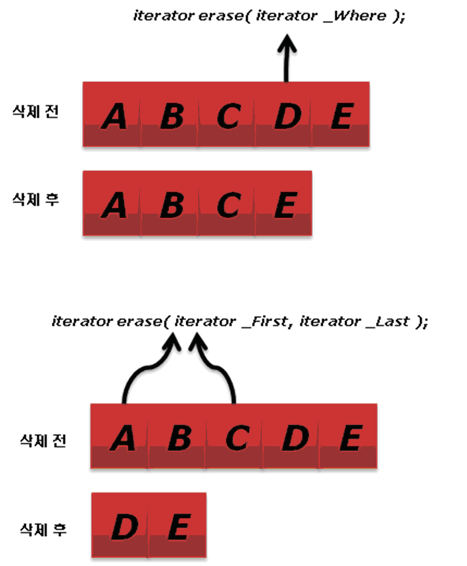
[그림 6] vector의 erase
첫 번째 erase는 지정한 위치의 요소를 삭제합니다. 다음은 첫 번째 요소를 삭제하는 코드입니다.
vector1.erase( vector1.begin() );두 번째 erase는 지정한 반복자 요소만큼 삭제합니다. 다음 코드는 vector1의 첫 번째 요소에서 마지막까지 모두 삭제합니다.
vector1.erase( vector1.begin(), vector1.end() );다음은 erase 사용을 보여주는 예제입니다.
[리스트 3] erase 사용
void main()
{
vector< int > vector1;
vector1.push_back(10);
vector1.push_back(20);
vector1.push_back(30);
vector1.push_back(40);
vector1.push_back(50);
int Count = vector1.size();
for( int i = 0; i < Count; ++i )
{
cout << "vector 1 : " << vector1[i] << endl;
}
cout << endl;
cout << "erase 테스트 1" << endl;
// 첫 번째 데이터 삭제
vector1.erase( vector1.begin() );
// 20, 30, 40, 50 출력
Count = vector1.size();
for( int i = 0; i < Count; ++i )
{
cout << "vector 1 : " << vector1[i] << endl;
}
cout << endl << "erase 테스트" << endl;
// 첫 번째 데이터에서 마지막까지 삭제한다.
vector< int >::iterator iterPos = vector1.begin();
vector1.erase( iterPos, vector1.end() );
if( vector1.empty() )
{
cout << "vector1에 아무 것도 없습니다" << endl;
}
}
결과 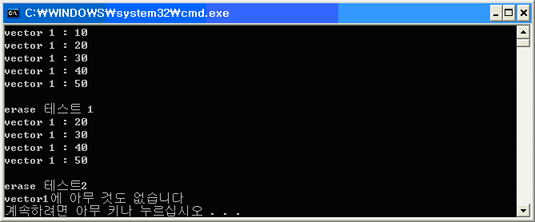
4.5.1.4 assign
vector를 어떤 특정 데이터로 채울 때는 assign을 사용하면 됩니다. 사용 방식은 두 가지가 있습니다. 첫 번째는 특정 값으로 채우는 방법이고, 두 번째는 다른 vector의 반복자로 지정한 영역에 있는 원소로 채우는 방법입니다. 만약 assign을 사용한 vector에 이미 데이터가 있다면 기존의 것은 모두 지우고 채웁니다.
원형 : void assign( size_type _Count, const Type& _Val );
template<class InputIterator> void assign( InputIterator _First, InputIterator _Last );
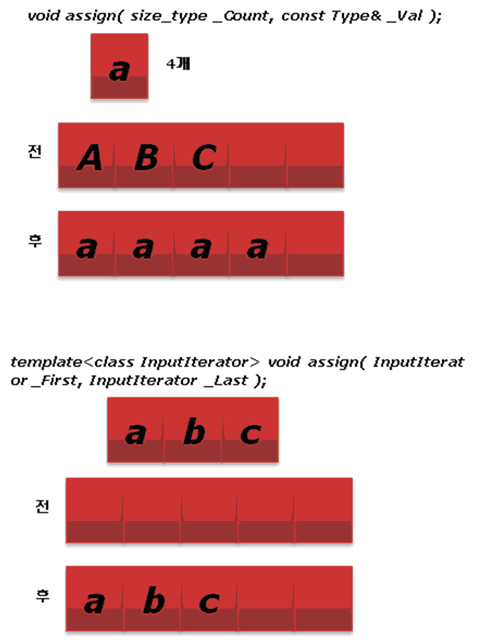
[그림 7] assign
첫 번째 assign은 지정 데이터를 지정 개수만큼 채워줍니다. 숫자 4를 7개 채웁니다.
vector1.assign( 7, 4 );두 번째 assign은 다른 vector의 반복자로 지정한 영역으로 채워줍니다.
vector1.erase( vector1.begin(), vector1.end() );다음은 assign을 사용법을 보여주는 예제입니다.
[리스트 4] assign
void main()
{
vector< int > vector1;
// 4를 7개 채운다.
vector1.assign( 7, 4 );
int Count = vector1.size();
for( int i = 0; i < Count; ++i )
{
cout << "vector 1 : " << vector1[i] << endl;
}
cout << endl;
vector< int > vector2;
vector2.push_back(10);
vector2.push_back(20);
vector2.push_back(30);
// vector2의 요소로 채운다
vector1.assign( vector2.begin(), vector2.end() );
Count = vector1.size();
for( int i = 0; i < Count; ++i )
{
cout << "vector 1 : " << vector1[i] << endl;
}
cout << endl;
}
결과 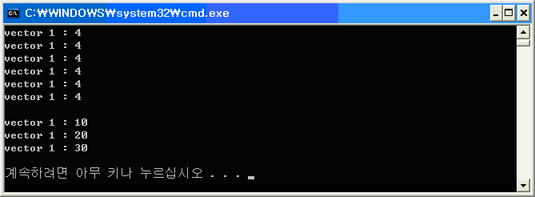
4.5.1.5 reserve
vector는 사용할 메모리 영역을 처음 선언할 때 정해진 값만큼 할당한 후 이 크기를 넘어서게 사용하면 현재 할당한 크기의 2배의 크기로 재할당합니다. vector에 어느 정도의 데이터를 저장할지 가늠할 수 있고, vector 사용 도중에 재할당이 일어나는 것을 피하려면 사용할 만큼의 크기를 미리 지정해야 합니다. 참고로 reserve로 지정할 수 있는 크기는 vector에서 할당하는 최소의 크기보다는 커야 합니다.
원형 : void reserve( size_type _Count );

[그림 8] reserve
10개의 원소를 채울 수 있는 공간 확보
vector1.reserve( 10 );4.5.1.6 swap
vector1과 vector2가 있을 때 두 개의 vector간에 서로 데이터를 맞바꾸기를 할 때 사용합니다.
원형 : void swap( vector<Type, Allocator>& _Right );
friend void swap( vector<Type, Allocator >& _Left, vector<Type, Allocator >& _Right );
[그림 9] swap
vector1과 vector2를 swap
vector1.swap( vector2 );swap을 사용하는 예제입니다.
[리스트 5] Swap
void main()
{
vector< int > vector1;
vector1.push_back(1);
vector1.push_back(2);
vector1.push_back(3);
vector< int > vector2;
vector2.push_back(10);
vector2.push_back(20);
vector2.push_back(30);
vector2.push_back(40);
vector2.push_back(50);
int Count = vector1.size();
for( int i = 0; i < Count; ++i )
{
cout << "vector 1 : " << vector1[i] << endl;
}
cout << endl;
Count = vector2.size();
for( int i = 0; i < Count; ++i )
{
cout << "vector 2 : " << vector2[i] << endl;
}
cout << endl;
cout << endl;
cout << "vector1과vector2를swap" << endl;
vector1.swap(vector2);
Count = vector1.size();
for( int i = 0; i < Count; ++i )
{
cout << "vector 1 : " << vector1[i] << endl;
}
cout << endl;
Count = vector2.size();
for( int i = 0; i < Count; ++i )
{
cout << "vector 2 : " << vector2[i] << endl;
}
}
결과 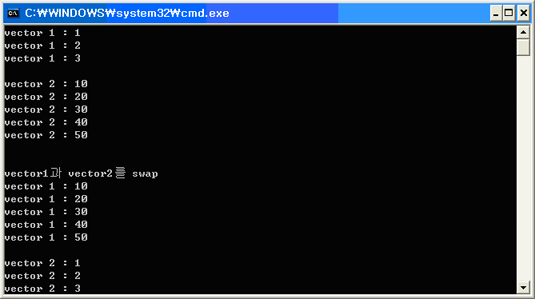
vector 중에서 가장 많이 사용하는 멤버를 중심으로 설명 하였습니다. vector의 모든 멤버를 설명하지는 않았으니 소개하지 않은 나머지 멤버까지 알고 싶다면 마이크로소프트의 MSDN에 나와 있는 것을 참고해 주세요.http://msdn.microsoft.com/en-us/library/sxcsf7y7.aspx
앞 회의 list 글을 보신 분들은 이번에 설명한 vector에서 소개한 front(), push_back(), pop_back(), erase() 등이 list의 멤버들과 사용 방법이나 결과가 같음을 알 수 있습니다. 이것이 STL를 사용하여 얻는 장점 중의 하나입니다.
STL에서 제공하는 컨테이너들은 서로 특성은 다르지만 사용 방법과 결과가 같기 때문에 하나만 잘 알며 다른 것들도 쉽게 배울 수 있습니다. 만약 STL의 컨테 이너를 사용하지 않고 독자적으로 구현하여 사용한다면 각각 사용 방법이 달라서 사용 방법을 배울 때마다 STL보다 더 많은 시간이 필요할 것이며, 함수 이름 을 보고 어떤 동작을 할지 각각의 라이브러리마다 숙지해야 하므로 유지보수에 좋지 않습니다.
vector는 배열과 비슷하고 사용하기 편리하여 많은 곳에서 사용합니다. 그러나 vector의 특성을 제대로 이해하지 못하고 잘못된 곳에 사용하면 심각한 성능 저 하가 일어날 수 있습니다(많은 데이터를 저장하고 있으며 빈번하게 중간에서 삽입, 삭제를 할 때). 그러니 꼭 적합한 장소에 사용해야 합니다.
과제
1. 이전 회의 글 중 ‘3.5 list를 사용한 스택’에서 list를 사용하여 LIFO 방식으로 스택을 만든 예제가 있는데 이것을 vector를 사용하여 만들어 보세요
2. ‘카트 라이더’와 같이 방을 만들어서 게임을 하는 온라인 게임에서 방에 있는 유저를 관리하는 부분을 vector를 사용하여 만들어 보세요. 기본적인 클래스 선언은 제시할 테니 구현만 하면 됩니다.
// 유저 정보
struct UserInfo
{
char acUserName[21]; // 이름
int Level; // 레벨
int Exp; // 경험치
};
// 게임 방의 유저를 관리하는 클래스
// 방에는 최대 6명까지 들어 갈 수 있다.
// 방에 들어 오는 순서 중 가장 먼저 들어 온 사람이 방장이 된다.
class GameRoomUser
{
public:
GameRoomUser();
~GameRoomUser();
// 방에 유저 추가
bool AddUser( UserInfo& tUserInfo );
// 방에서 유저 삭제.
// 만약 방장이 나가면 acMasterUserName에 새로운 방장의 이름을 설정 해야 된다.
bool DelUser( char* pcUserName );
// 방에 유저가 없는 지조사. 없으면 true 반환
bool IsEmpty();
// 방에 유저가 꽉 찼는지 조사. 꽉 찼다면 true 반환
bool IsFull();
// 특정 유저의 정보
UserInfo& GetUserOfName( char* pcName );
// 방장의 유저 정보
UserInfo& GetMasterUser();
// 가장 마지막에 방에 들어 온 유저의 정보
UserInfo& GetUserOfLastOrder();
// 특정 순서에 들어 온 유저를 쫒아낸다.
bool BanUser( int OrderNum );
// 모든 유저를 삭제한다.
void Clear();
private:
vector< UserInfo > Users;
char acMasterUserName[21]; // 방장의 이름
};
allocator = 할당자
http://ohyecloudy.com/pnotes/archives/250/
EASTL - 할당자(allocator)
07 Nov 2008EASTL - Electronic Arts Standard Template Library은 거대 게임 개발사인 EA가 C++ 표준 라이브러리인 STL을 게임 개발에 맞게 수정한 라이브러리이다.
EASTL에서 가장 많이 수정된 부분은 할당자인데, 이 부분만 살펴보자. STL의 할당자를 class-based에서 instance-based로 변경하자는 Halpern proposal를 따랐다.
EASTL은 instance-based 할당자(Allocator)를 사용한다.
template <class T>
class allocator
{
typedef T* pointer;
...
pointer allocate(...);
void deallocate(...);
void construct(...);
void destroy(...);
...
}
std::allocator는 class-based 할당자이다. 위와 같이 정의된 할당자를 인스턴스(instance) 단위로 사용하지 않고 클래스 단위로 사용한다. 할당자를 사용하는 컨테이너를 예로 들면, std::vector<int, std::allocator<int> > a와std::vector<int, std::allocator<int> > b는 각기 다른 인스턴스이지만 각자 따로 메모리를 할당해 쓰는 게 아니라 템플릿 인스턴스화(template instantiation)를 거친 std::allocator<int>에서 정의한 메모리를 사용하게 된다.
할당자 안에 객체별 전용 데이터를 허용하지 않는 제약이 생긴 이유는 표준 라이브러리의 런타임/메모리 효율에 대한 강한 압박 때문이었다. 리스트 하나만 놓고 보면 할당자가 차지하는 오버헤드는 새 발의 피 수준일지 모르나, 그 리스트에 포함된 모든 링크가 데이터를 하나씩 물고 있다면 과다 출혈로 새가 쓰러질 수도 있는 것이다.
- TC++PL 19.4.3 일반화된 할당자
비야네 아저씨는 왜 이렇게 했을까? TC++PL(The C++ Programming Language)를 찾아보니 런타임과 메모리 효율 때문이라고 한다. 메모리 효율과 속도만을 생각한다면 인스턴스마다 할당자를 따로 관리할 필요 없는 class-based 할당자로 제한하는 것도 좋은 선택이라고 생각된다.
그러나 세상에는 공짜가 없다. class-based 할당자라서 애초 목표인 할당자와 컨테이너 분리가 제대로 이루어지지 않았다. 템플릿 매개변수로 넘겨줘서 할당자 정의를 하는데, 할당자가 다르면 다른 클래스로 정의된다. 그 결과 반복자(iterator) 비교가 불가능해지는데, std::range_equal(SharedList.begin(), SharedList.end(), TestList.begin(), TestList.end())과 같은 STL 알고리즘을 SharedList와 TestList의 할당자가 다르다면 사용할 수 없게 된다. 즉, 할당자가 다른 컨테이너 사이의 연산이 불가능해지는 상황이 발생하게 된다.
instance-based 할당자를 쓰면 어떤 할당자를 쓰던지 상관없이 컨테이너 사이의 연산이 가능해진다. 그리고 타입에 얽매이지 않고 용도에 맞게 할당자를 골라 쓸 수 있다. 가령 임시로 쓰고 버릴 컨테이너 같은 경우에 힙에서 메모리를 할당받지 않고 로컬 메모리를 사용해서 성능상 페널티를 줄일 수 있게 된다. 단, 인스턴스마다 할당자의 정보를 저장해야 하는 메모리상의 손해는 감수해야 한다.
template <class T, class Allocator = eastl::allocator>
class container
{
public:
typedef Allocator allocator_type;
...
public:
container(const allocator_type& allocator = allocator_type());
...
allocator_type& get_allocator();
const allocator_type& get_allocator() const;
void set_allocator(allocator_type& allocator);
};
EASTL에서는 rebind 함수를 제거하고 할당자에 템플릿을 제거했다. 기존 컨테이너와의 호환성을 위해 템플릿 매개변수 중 할당자는 그대로 놔뒀으며eastl::allocator를 상속받은 클래스를 컨테이너를 생성할 때 매개변수로 넣어 주거나 set_allocator 멤버 함수의 매개변수로 넣어서 할당자를 변경할 수 있다. 물론 해당 인스턴스만 변경한다.
Allocator의 rebind가 제거됐다.
template <class T>
class allocator
{
public:
...
template <class U> struct rebind { typedef allocator<U> other; };
};
아무 타입이나 할당할 수 있게 하는 rebind 함수는 컨테이너를 생성하는 데 필요한 데이터를 할당하는데 사용한다. 예를 들면 List 같은 경우 int와 같이 저장하는 데이터외에 Linked List를 구성하려면 앞,뒤 노드의 포인터를 저장할 공간이 추가로 필요하다. 이때 이 rebind 함수를 사용한다.
rebind 함수를 정의한 목적인 "아무 타입이나 할당" 때문에, 템플릿 함수일 수밖에 없다. 그 때문에 코드 부풀림(code bloat) 현상이 일어나고 그에 따른 성능에서 손해가 발생하게 된다.
template <class T, class Allocator = eastl::allocator>
class container
{
public:
...
typedef impl-defined node_type;
...
};
EASTL에서는 할당자의 rebind를 없애버리고 컨테이너가 사용하는 데이터 타입을 정의했다. 그리고 할당자를 템플릿 클래스가 아닌 클래스로 정의했다.
새로 만들지 않고 STL을 고쳐서 쓰는 건 현명한 판단이다.
STL은 신뢰하지 않는 사람들이 많은 라이브러리이다. C++ 표준 라이브러리인데도 말이다. EA 정도 규모의 개발 회사면 자체 표준 라이브러리 개발을 할 충분한 여력이 있다고 생각된다. 하지만 STL을 대체하는 라이브러리를 새로 만들기보단 STL에서 마음에 안 드는 부분을 개선했다. 라이브러리의 안정화에 드는 비용과 새로 만든 라이브러리의 교육 비용을 생각해보면 STL을 개선해서 사용하는 게 훨씬 합리적인 선택이라고 생각된다.
http://nedy.tistory.com/13
int값의 STL vector를 받아 배열내의 모든 홀수를 출력하는 C++ 함수 작성
#include "stdio.h"
#include //vector include
void main()
{
std::vector intList; // vector 변수 선언
intList.clear(); // 변수 초기화 안해줘도 되지만 변수는 초기화 해주는 습관을...
char szInput[1024] = { 0, }; // 입력을 받을 버퍼, 종료 문자를 입력 받기 위해서 문자열로 선언
printf("Input Number(Quit is q) : ");
scanf("%s", szInput);
while(strcmp(szInput, "q") != 0) // q가 들어오면 종료
{
int nNumber = atoi(szInput); // 들어온 문자열을 int로 변환
intList.push_back(nNumber); // vector에 삽입
printf("Input Number(Quit is q) : ");
scanf("%s", szInput);
}
for(int i = 0; i < intList.size(); i++) // vector의 접근은 일반 배열의 접근 방식이 가능하므로
{
int nNumber = intList[i]; // 삽입 되어있는 값 얻기
if((nNumber % 2) != 0) // 홀수 인지 판별
printf("%d ", nNumber);
}
intList.clear(); // vector의 사용을 마쳤으므로 다시 초기화
printf("\n");
}
// STL vector의 간단한 사용법
// STL에서의 벡터(vector)는 동적 배열이다
// vector를 사용하기 위한 해더파일 인클루드
#include <vector>
using namespace std;
// 선언
// int 타입으로 선언되었기 때문에 4바이트가 메모리에 할당 된 것 처럼 보일 수 있으나
// 실제로는 크기가 0인 즉, 비어있는 배열이 선언된 것이다
vector<int> list;
// list란 동적배열에 데이터 5를 추가함
// push_back 함수의 인자는 반드시 선언된 타입과 같아야한다
// 여기서는 정수(int)타입의 5를 넘겨주었다
list.push_back(5);
// iterator(반복자)를 생성
// iterator는 객체의 포인터형이다
// iterator에 객체의 첫 원소의 주소를 넘겨준다
// iterator 역시 선언한 타입과 반드시 동일한 타입으로 선언해야한다
// list와 동일한 타입의 interator를 생성
vector<int>::iterator i;
// i(interator)에 list의 첫 원소의 주소를 넘겨줌
// i가 list의 마지막 원소의 주소와 같지 않다면 루프
// i(interator) 증가(즉, 다음 list의 주소로 넘어감)
for(i = list.begin(); i != list.end(); i++)
{
// i(interator)가 가르키는 list의 현재 배열 값을 출력
printf("%d\n", *i);
}
// 원소 삭제
vector<int>::iterator i;
for(i = list.begin(); i != list.end(); i++)
{
// i(interator)가 가르키는 list의 현재 배열 값을 지운다
// erase 함수를 사용하여 원소를 삭제할 수 있다
list.erase(i);
}
[출처] stl vector 사용법|작성자 바들바들
'차근차근 > OpenCV' 카테고리의 다른 글
| SURF에 의한 특징점 검출 (0) | 2014.08.06 |
|---|---|
| 외부에서 이미지 입력받기 (0) | 2014.08.06 |
| union CvMat::<unnamed> CvMat::data (0) | 2014.08.06 |
| Laplacian 라플라시안 (0) | 2014.08.05 |
| 프리만 체인 (0) | 2014.08.05 |
'차근차근/OpenCV'의 다른글
- 현재글std::vector<cv::String,std::allocator<cv::String>>ldata>